Project 1: Song Analysis
Design Checks: September 24th – September 26th
Design Check due: September 24 at 9:00 PM EST (no late days allowed)
Implementation: due October 1 at 9:00 PM EST (up to 3 late days allowed ONLY if both you and your partner have late days remaining)
In this project, students will work with data sets of varying sizes, get an introduction to machine learning, and practice implementing written algorithms.
Section 1: Background
Tim has decided to unleash a special episode of Tim Talk called Tim Sings! Tim is running out of time, and he needs your help. Tim has a list of songs whose genres are unknown. It is up to you to build a program that takes in the lyrics of a song with an unknown genre and finds the most similar song with a known genre.
Part 1: Methodology
You will build a program that takes in lyrics for a song and determines its genre. Rather than hard-coding a set of rules, you’ll use machine learning to classify songs.
We’ll provide you with a set of training data: song lyrics with known genres. When you want to classify a new song into its genre, you will find the most similar song in the training data and return its genre.
In order to find the most similar song in the training data, you will implement the nearest neighbor algorithm. This will require calculating term-frequency-inverse document frequency (tf-idf) weights for every song. These weights are essentially word counts, modified by how common various words are. You’ll calculate the same weights for the input song. Then, you’ll compare the input song’s weights to each song in the training data using cosine similarity, a measure of the similarity of two sets of weights.
Part 2: tf-idf
tf-idf, or Term Frequency-Inverse Document Frequency, is a metric that represents a given term’s importance within a corpus (i.e., a set of documents, such as the training data). tf-idf is often used in text search algorithms (like Google!), keyword extraction, information retrieval, and natural language processing.
Part 2.1: Term Frequency (tf)
The Term Frequency of a word i is the number of times the word appears in a certain document d. Given the document: “Tik Tok on the clock, the party don’t stop”. The term frequencies would be as follows:
| Tik | Tok | on | the | clock | party | don’t | stop |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 |
Part 2.2: Inverse Document Frequency (idf)
Inverse Document Frequency is used to scale up the importance of words that occur with less frequency in the data (and to scale down less important words). To compute Inverse Document Frequency, we first need to get the fraction of the total number of documents in the corpus n over the number of documents in which a particular term i appears in the training data n~i~. Once this fraction is found, idf can be computed by taking the natural logarithm of the fraction. In computer science, the natural log is often represented as log(x) and not necessarily ln(x).
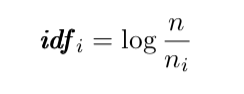
Consider this corpus:
| Doc 1 | Doc 2 | Doc 3 | Doc 4 | Doc 5 | Doc 6 | Doc 7 |
|---|---|---|---|---|---|---|
| Apple | Banana | Watermelon | Mango | Strawberry Strawberry | Kiwi Kiwi Strawberry | Strawberry Banana |
To calculate the idf score of “strawberry,” we would first identify n, the total number of documents (in this case 7). Then, we would divide by the number of documents “strawberry” appears in, n~i~. To find idf, we take the natural logarithm of n/n~i~, so ln (7/3) = .85. In order to get the natural log, make sure you use Python’s math.log function.
Part 2.3: Term Frequency-Inverse Document Frequency (tf-idf)
For our purposes, we want to use both term frequency and inverse document frequency in order to understand how important a single term is to a document in the context of the corpus. The tf-idf value is the product of the term frequency and inverse document frequency:
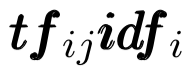
Where tf~ij~ represents the frequency of the term i in the document j and idf~i~ represents the inverse document frequency of the term i in the corpus as a whole.
For the above corpus, the tf-idf weights for Doc 6 would be:
| Kiwi | Strawberry |
|---|---|
| 2 * ln(7/1) | 1 * ln(7/3) |
Part 3: Cosine Similarity
In order to compare the tf-idf weights of two songs, you’ll use cosine similarity (for which we have provided an implementation). The cosine similarity of two identical documents is 1, and the cosine similarity of documents that share no words in common is 0. Beyond that, it will be higher when documents share higher-weighted words in common.
Part 4: Nearest Neighbor
Finally, you will implement the nearest neighbor algorithm, which outputs the song in our training data that is most similar to the input song using cosine similarity. This will allow us to classify the input song to have the same genre as the song most similar to it.
Section 2: Project Roadmap
-
Fill out the Partner Form. In this class, all projects will be in a group format, where you will have one or more partners to collaborate with, depending on the project. For this project, you will have one group partner to work through this project with.
The partner form will be posted on EdStem. Both you and your partner MUST attend the design check. If you do not attend the design check, you will not receive credit for the project.
- Design Check: Answer the design check questions and begin thinking about the return types of the functions that you will create and how they may work with your intended program organization.
- Implementation: In a later section, you will be asked to implement a series of functions that will allow you to classify songs based on their lyrics. You will be given a skeleton code that will help you get started.
- Testing: You will also be evaluated based on the testing of your implementation. Make sure that your code works for a variety of cases and consider where your implementation may fail.
- Style and Design: Be sure to follow all of the style and design guidelines outlined in the cs0112 python style guide.
Section 3: Design Check
For the design check, only one of you and your partner will be expected to hand in README.txt with block comments answering the questions asked below.
- After reading through the handout, demonstrate your understanding of tf-idf by answering the following questions:
- The Term Frequency of a word
iis the number of times the word appears in a certain documentd. Given the document: “the dog bit the man” — what are the term frequencies? - What do
tfijandidfirepresent? - What is the cosine similarity of two identical documents?
- Consider the following corpus.
- What is the idf score of “mango”?
- What are the tf-idf weights for Doc 3?
Doc 1 Doc 2 Doc 3 Doc 4 Mango Strawberry Mango Starfruit Watermelon Watermelon Strawberry Banana Mango - The Term Frequency of a word
- Being able to test your program is an important step in deciding how accurate your genre classifier is. After reading the handout, consider ways that you could test the program and its accuracy.
Note: Submit the README.txt file on EdStem.
Section 4: Setup
In working through this assignment, there are several components the algorithms can be broken into: TF, IDF, TF-IDF, and Nearest-Neighbor. These components are used in sequential order and build on each other. We recommend that you complete the project in the following order:
compute_tfcompute_idfcompute_tf_idfcompute_corpus_tf_idfnearest_neighbor
Three additional functions have been provided to you: create_corpus, cosine_similarity, and main.
Section 5: Implementation
In this project, you will be implementing a series of functions that will allow you to classify songs based on their lyrics. You will be given a skeleton code that will help you get started.
Notice the implementation of the create_corpus function. This function reads a CSV file and sets up a data set (i.e., a corpus) of songs. The corpus is a dictionary where the keys are song ids and the values are the lyrics of the song. The lyrics are stored as a list of strings, where each string is a word in the song. The corpus is used to calculate the tf-idf values for each song.
Task 1: Check the dataclass Song in the stencil code. Get comfortable with the dataclass and understand how it is used in the create_corpus function!
First, you will need to implement the compute_tf function. This function calculates the term frequency of a word in a song. The term frequency of a word is the number of times the word appears in a song. The function takes in a list of strings representing the lyrics for a song and produces a dictionary containing the term frequency where the key is the term and the value is the frequency for that term.
Task 2: Implement compute_tf. Write tests for this function in the test file.
Next, you will need to implement the compute_idf function. This function calculates the Inverse Document Frequency for each song in your corpus. The Inverse Document Frequency is used to scale up the importance of words that occur with less frequency in the data. The function takes in a corpus of songs and produces a dictionary from words to idf values (floats).
Task 3: Implement compute_idf. Write tests for this function in the test file.
Next, you will need to implement the compute_tf_idf function. This function calculates the Term Frequency - Inverse Document Frequency. This function takes in a list of strings representing song lyrics and a dictionary of idf values and outputs a dictionary where the keys are words from the song and the values are tf-idf weights. Try using the functions you have already implemented!
Task 4: Implement compute_tf_idf. Write tests for this function in the test file.
Then, you will need to implement the compute_corpus_tf_idf function. This function calculates the tf-idf values for every song in your corpus. This function takes in a corpus and a dictionary of idf values and produces a dictionary where the keys are song ids and the values are tf-idf dictionaries. This function should call compute_tf_idf.
Task 5: Implement compute_corpus_tf_idf. Write tests for this function in the test file.
We have provided you with a function called cosine_similarity. This function calculates the cosine similarity of two dictionaries that are the result of tf-idf calculations. The cosine similarity of two vectors is the dot product of the two vectors divided by the product of the magnitude of the two vectors.
Task 6: Read through the cosine_similarity function. Check how we calculate the dot product and the magnitude of the vectors.
Now, using the functions you have implemented, you will implement the nearest_neighbor function. This function calculates the nearest neighbor of a novel song. This function takes in a string representing song lyrics, a corpus of songs, a dictionary of tf-idf dictionaries (as produced by compute_corpus_tf_idf) and a dictionary of idf weights and outputs the Song that is most similar to the lyrics (as measured by cosine similarity). This function should call compute_tf_idf and cosine_similarity.
Task 7: Implement nearest_neighbor. Write tests for this function in the test file.
Finally, we have provided you with a function called main. This function reads in a CSV file of song lyrics and uses the functions you have implemented to classify the genre of a song.
Task 8: Run the main function and check if your implementation is working as expected.
Section 6: Testing
For this project, we would like you to put all of your tests in song_analysis_test.py. You should test all of the functions you write; you don’t need to write tests for create_corpus or cosine_similarity. Please follow the testing section of the design and clarity guide.
You can also run your code on a real data set, which you can find here.
Section 7: Submission
Only one of you and your partner needs to submit your code on Gradescope. You may submit as many times as you want – only your latest submission will be graded. This means that if you submit after the deadline, you will be using a late day – so do NOT submit after the deadline unless you plan on using late days. Again, BOTH you and your partner must have late days to use them.
Please follow the design and clarity guide–part of your grade will be for code style and clarity. After completing the project, you will submit:
README.txtsong_analysis.pysong_analysis_test.py
Because all we need are the files, you do not need to submit the whole project folder. As long as the file you create has the same name as what needs to be submitted, you’re good to go! If you are using late days, make sure to make a note of that in your README. Remember, you may only use a maximum of 3 late days per assignment. If the assignment is late (and you do NOT have anymore late days) no credit will be given.
Submit your work on Gradescope. Please don’t put your name anywhere in any of the handin files–we grade assigments anonymously!